

How Browsers Work to Render Websites
In this article, I will dive deep into understanding how the browser renders a webpage.


User's today have the shortest attention spans and the highest expectations of web and mobile. We expect that every webpage we visit is interactive and smooth, should load quickly and have effortless UX/UI where we don't have to think too much about how to get the information we need.
If I wait too long for a web page to load, I get frustrated which results in me dropping and losing interest–especially if it's an online store or a banking site.
So what does this mean?
To write sites and applications with high performance optimization, we need to understand how HTML, CSS and Javascript are handled by the browser. Understanding how browsers work under the hood will help ensure that we write code that runs efficiently and quickly to deliver performant sites to the user.
Browser Components
A browser is made up of the following components:
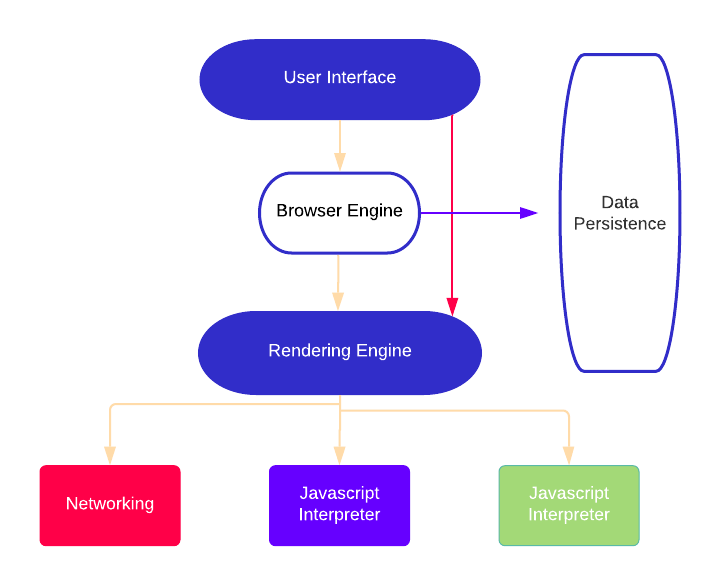
The User Interface: This is everything that the user can visually see. The address bar, back and forward button, tabs, bookmarking menu, etc. This is every part of the browser display except the window where you see the requested page.
The Browser Engine: This is responsible for the actions between the UI and the rendering engine.
The Rendering Engine: The Rendering Engine is what we'll be focusing on. This component of a browser is responsible for displaying the requested content such as the HTML and CSS. It parses the HTML and CSS and displays the parsed content on the screen, which is what is shown to the users.
Networking: The networking component is responsible for network calls such as HTTP requests.
UI Backend: Used for drawing basic widgets like boxes and windows. The backend exposes a generic interface that is not platform specific. Underneath the hood, it uses operating system UI methods.
Javascript Interpreter: Used to parse and execute Javascript code.
Data Storage: This is a persistence layer of a browser. The browser may need to save all kinds of data locally, such as cookies. Some commonly used storage mechanisms that fall under this category are localStorage, indexedDB, WebSQL, and FileSystem.
Basic Rendering Engine Flow
We'll be focusing on the Rendering Engine - this is responsible for the daily creative magic that is shown to us when we type in a web address.
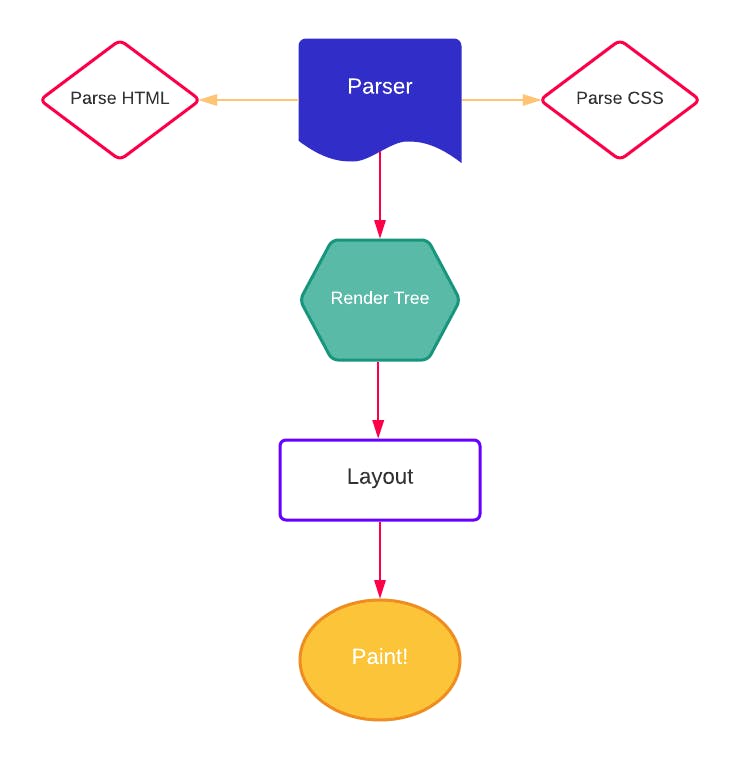
The following is the basic flow of the Render Engine:
Let's dive a little deeper into it.
Parser
A parser translates a document into a structure that your code can use. There are two kinds of parsers that come with the Render Engine. Conventional Parser and Unconventional Parser.
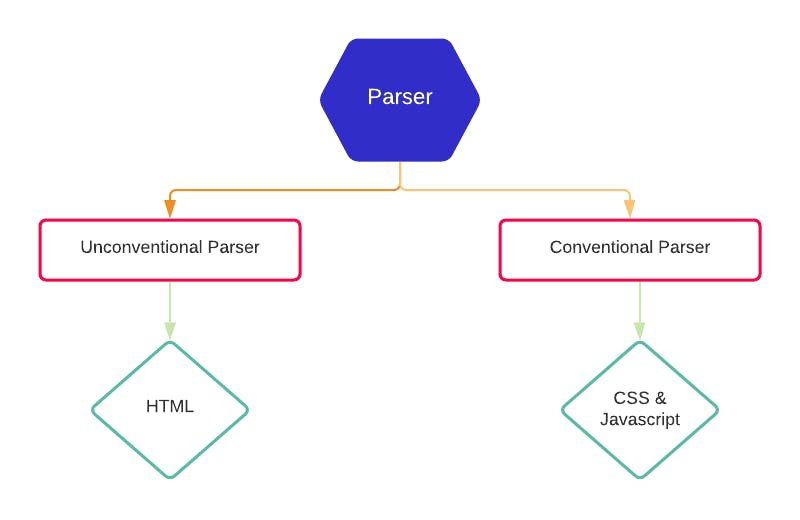
The unconventional parser is meant to parse HTML. It's more forgiving with the code — meaning if you make a mistake in your HTML code, the browser will still render the code correctly by guessing what you messed up on. So let's say you forget to add a closing tag, the browser will add it on its own and display the correct structure of the webpage. it won't throw an error, unlike other more strict languages such as CSS and Javascript.
Meanwhile, the conventional parser is less forgiving and will throw up an error alert if there is a mistake in your code. For example, if you forget to add the the closing bracket in your CSS, the browser will not run the CSS, resulting in an unstyled webpage.
So how does the browser parse the HTML document? In these 4 steps:
- Have a valid HTML document
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Web Page Performance</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>HELLO WORLD</h1>
<p>How is everyone doing
<script src="index.js"></script>
</body>
</html>
This is a valid HTML document even though the closing </p> tag is missing. The browser will close it on its own.
- Look for the opening tag
- Match with closing tag
- Once matched, the Render Tree is built
Render Tree
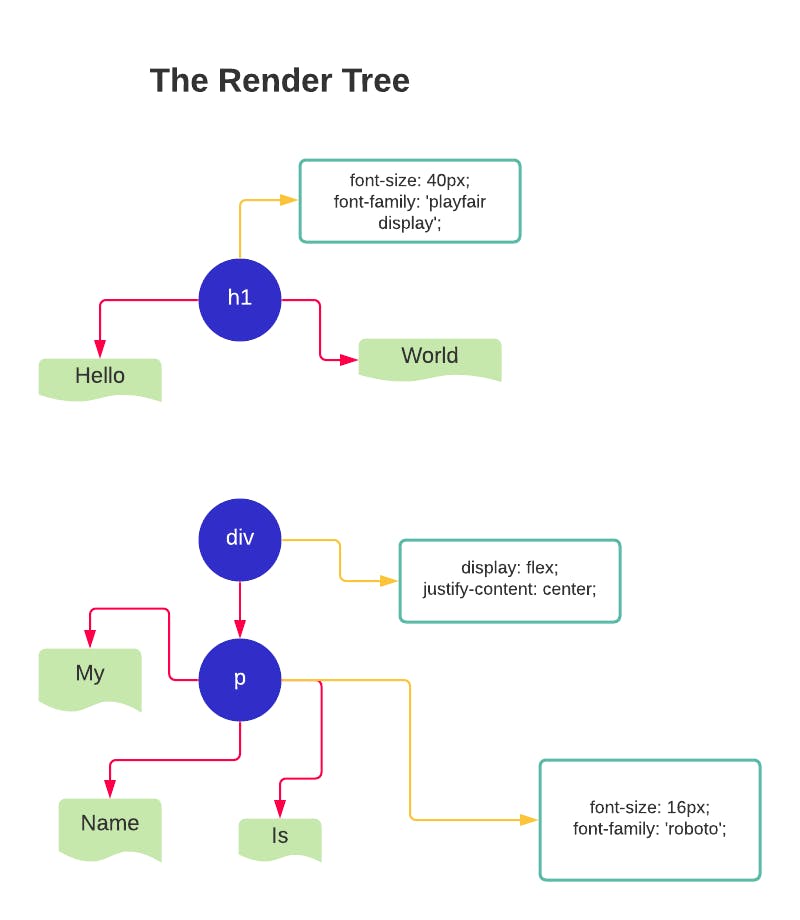
The Render Tree is made up of the DOM (Document Object Model) and the CSSOM (CSS Object Model). One of the most important properties of the Render Tree is that it only captures visible content.
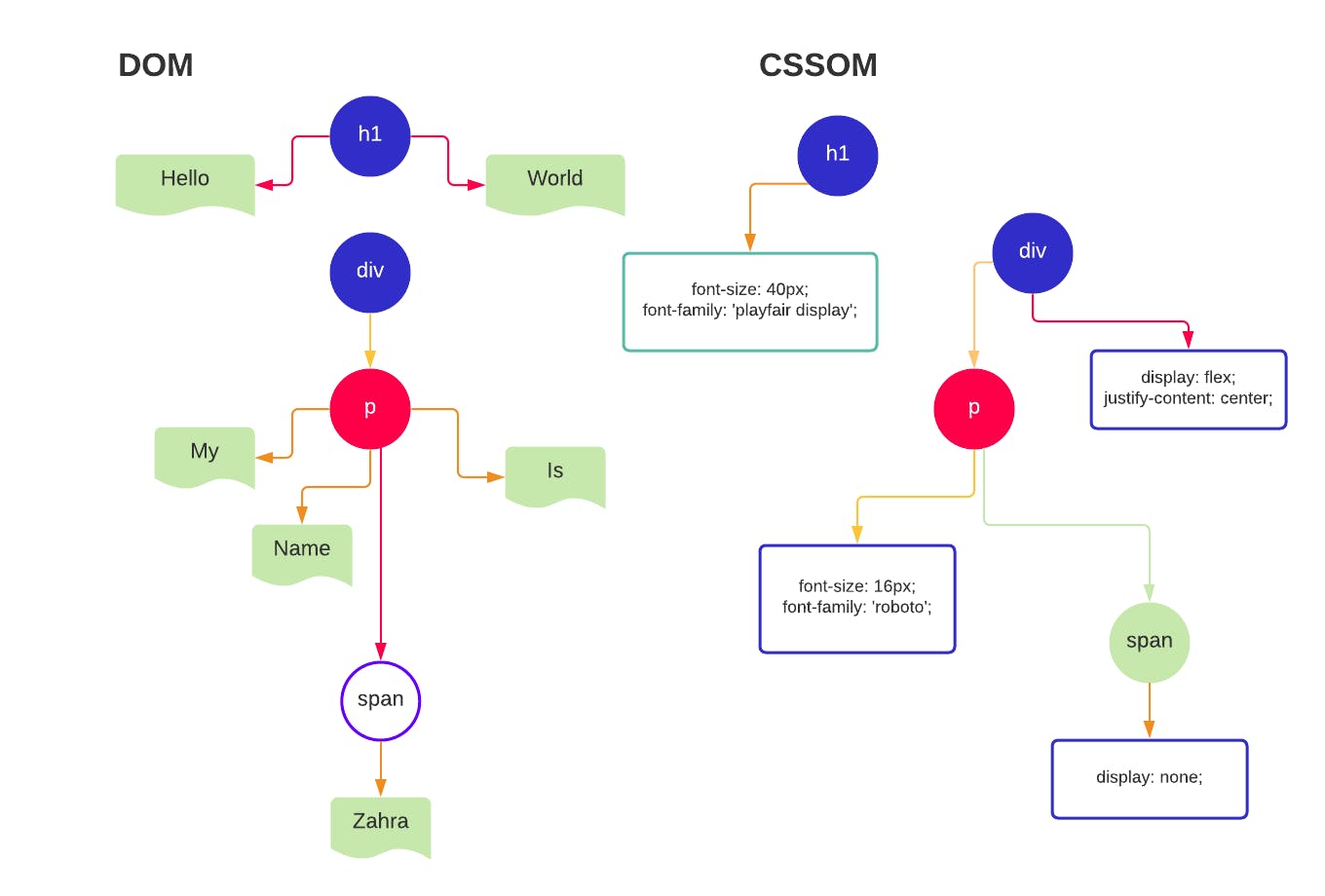
The DOM contains all of the HTML elements and the content inside of the tags. Its constructed incrementally as the bytes arrive on the "wire." But unlike HTML parsing, CSSOM is not incremental. The browser would need to reach the entire CSS file in order for a page to render with styling. This is why it's important to break up your stylesheets into small chunks so that as the network is reaching for the HTML document incrementally, the stylesheet associated with the HTML loads with it. Otherwise, if you render the DOM without the CSS (or let's say you have a mistake in your CSS) you'd get an unstyled page. The CSS will not load.
DOM + CSSOM = Render Tree(s) a new hybrid tree is created once the CSS is loaded.
 (see video).
(see video).
Notice that the span tag is not included in The Render Tree because it doesn't actually show up on the page. The styling of the span is set to display: none; so the browser won't render it, therefore, excluding the node.
Once the Render Tree is ready, the browser will perform the Layout flow.
Layout
Also known as reflow, computes the size of all of the nodes. Once the layout is complete, it renders the pixels onto the screen. The way this works is:
- The Layout calculates the position and size of the file. Most of the time, it's possible to compute the geometry in one pass.
- The recursive process begins at the root object (
<html>) and works its way down the tree to figure out where everything sits.
There's a term called the Dirty Bits System which is a system that makes sure the browsers doesn't need to do a full layout on every interaction. It will layout in batches incrementally. However, there is also something called immediate layout which, if you do a font-size change or if it needs to do a browser resize, it will relayout the entire document at once.
And then finally, when the browser completes the Layout process, it moves onto the Paint stage.
Paint
The paint stage is what takes all the information from the render tree and it'll do the calls to the network to paint the pixels onto the screen. The render tree is traversed and the paint() method is used to display content on the page. It literally gives you the visual output that you see on your webpage. The way this works is it will layout the render trees which is responsible for the structure of the nodes on a webpage. It's an incremental process that works from creating "bottom up" layouts (z-index, position absolute, etc) for a lack of a better word for this.
It's an intense 12-step process that has a painting order. It will paint the background color, background image, border, children, outline, etc, to make sure that everything is rendered in the correct order.
Conclusion
And that is the high-level explanation of how the Render Engine works! There is definitely MORE to it and I've listed some sources towards the end if you want to dig deeper. It's an interesting topic and will overall make you a better engineer to understand how the Internet/Browser works.
Sources: